
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- ANOVA
- 히스토그램
- spss
- 태그를 입력해 주세요.
- 창평
- R
- categorical variable
- 패수
- 풍백
- 단군
- 고구려
- linear regression
- t test
- 선형회귀분석
- 기자조선
- 독사방여기요
- 후한서
- 지리지
- post hoc test
- 유주
- Histogram
- repeated measures ANOVA
- 한서
- 통계
- 기자
- 우분투
- 한서지리지
- 낙랑군
- 신라
- 통계학
- Today
- Total
목록2013/07 (11)
獨斷論
 채변봉투란 무엇인가?
채변봉투란 무엇인가?
70-80년대에는 우리나라 기생충 박멸을 위해 온 힘을 기울여 초중고교에서는 1년에 2번 전교생의 똥을 받아 학교에 제출해야했다. 그날만 되면 교실 안에 은근한 똥내가 진동을 했다. ㅋㅋ 못가져온 아이들의 사정을 들어보면 - 변비에요 - 설사했어요 - 똥이 안나와요 - 받아놓고 안가져 왔어요... 보통 다른 일 같으면 준비물을 안가져왔을때에는 선생님께 종아리 맞는걸로 끝났으나 채변봉투는 혼내는걸로 끝나지 않고 학교 화장실에서 대변을 받아 그날 다 제출해야 했다. 그날만 되면 교실뿐만 아니라 교무실에 똥내가 진동했다. ㅋㅋ 학생들이 손바닥만한 채변봉투에 똥을 담아 내면 선생들은 서류봉투보다 좀더 큰 종이봉투에 전학년(약 60-80명)의 채변봉투를 한데 담아 교무실로 가져갔다가 한꺼번에 변 검사하는 곳으로 ..
http://dogmas.tistory.com/186에서 사용된 데이터를 이용할 것이므로 데이터를 지웠다면 다시 수행해야 한다. t test의 가장 큰 문제는 데이터가 정규분포를 가지냐는 점이다. 정규분포의 제약이 없는 방법으로 Wilcoxon test가 있는데 dependent sample에서 어떻게 수행하는지 알아보자. 기본적인 문법은 아래와 같은데 wilcox.test(x, y = NULL, alternative = c("two.sided", "less", "greater"), mu = 0, paired = FALSE, exact = NULL, correct = TRUE, conf.int = FALSE, conf.level = 0.95, ...) Formula를 사용하지 않고 수행하려면 아래와 같이..
Dependent measures t test는 하나의 그룹의 측정값을 시간에 따라 측정했을때 얼마나 차이가 나는지 보는 것이며 repeated measures의 한 종류이다. 예를들어 식욕부진환자가 가족치료요법 전후로 몸무게가 어떻게 변화하였는지 본다면 dependent measures t test를 사용하여야만 할 것이다. 이를 R에서 수행해보자. R에는 많은 데이터베이스를 제공하는데 MASS 패키지에 anorexia가 식욕부진환자의 데이터이다. 이를 불러들이기 위하여 아래와 같이 수행한다. > data(anorexia, package="MASS") > anorexia Treat Prewt Postwt 1 Cont 80.7 80.2 2 Cont 89.4 80.1 3 Cont 91.8 86.4 4 Co..
 Independent samples t test 두번째 (통계 R 초급 - 3)
Independent samples t test 두번째 (통계 R 초급 - 3)
지난시간에는 Independent samples t test를 R에서 어떻게 수행하는지 알아보았는데 이번에는 이에 대한 power analysis를 어떻게 수행하는지 알아보자. R 터미널에서 help(power.t.test)라고 치면 이에 대한 도움말을 볼수있으니 참고하도록 하자. 대개 아래와 같은데... power.t.test(n = NULL, delta = NULL, sd = 1, sig.level = 0.05, power = NULL, type = c("two.sample", "one.sample", "paired"), alternative = c("two.sided", "one.sided"), strict = FALSE) n은 샘플의 observation 갯수이고 delta는 비교하고자 하는 두 ..
 Independent samples t test (통계 R 초급 - 2)
Independent samples t test (통계 R 초급 - 2)
서로 다른 두 그룹의 차이를 비교하는 것이 independent samples t test이다. 예를 들어 담배를 피는 사람들과 안피는 사람들 사이의 단기 기억력을 비교한다고 하자. 각각의 그룹에 대해서 단기간 기억력을 조사한 것을 각각의 변수에 저장하면 아래와 같다. > nonsmokers = c(18,22,21,17,20,17,23,20,22,21) > smokers = c(16,20,14,21,20,18,13,15,17,21) 대략의 결과를 예측해보려면 두 데이터에 대해서 boxplot을 그려보면 된다. > boxplot(nonsmokers,smokers,ylab="Scores on Digit Span Task", names=c("nonsmokers","smokers")) 그냥 한눈으로 봐도 두 평..
Student's t-test를 수행하는 통계R의 명령어는 t.test()이다. R console에서 help("t.test")라고 치면 이에 대한 설명을 볼수 있다. 우선 첨부된 파일을 내려받아 통계R에서 불러들인다. 첨부파일: 이제 위 데이터파일을 R에서 불러오는데 다음과 같이 하면 된다. > temp.dat = read.csv("bodyt_heartr.csv") > temp.dat > names(temp.dat) 위와같이 실행하면 temp.dat라는 변수에 csv의 파일에 있던 데이터가 들어가게 된다. 주의할점은 현재 디렉토리와 bodyt_heartr.csv가 있는 디렉토리가 같아야 하는데 현재 R의 작업디렉토리는 getwd()를 실행하면 얻을 수 있다. 작업디릭토리를 바꾸러면 setwd("c:/t..
R에서 간단한 linear regression을 수행하는 방법을 알아보자. 우선 종속변수를 y라 하고 독립변수를 x라 했을때 두 변수에 임의 값을 지정하자. > x = c(1.1, 2.5, 3.1, 4.9, 5.9, 8.1) > y = c(1.2, 6.4, 9.0, 23.5, 38, 61.1) 이 두 변수를 이용하여 linear regression을 수행하는 방법은 아주 간단하고 아래와 같다. > lm(y ~ x) Call: lm(formula = y ~ x) Coefficients: (Intercept) x -14.552 8.848 위 선형회귀분석의 결과를 저장하고자 한다면 아래와 같이 수행하면 된다. > lm.results = lm(y ~ x) > summary(lm.results) Call: lm(..
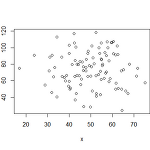 통계 R의 명령어 입문 (5): 상관관계(Correlation) 계산
통계 R의 명령어 입문 (5): 상관관계(Correlation) 계산
R에서 제공하는 상관관계(correlation)은 아래 세가지이다. Pearson's product moment correlation coefficient Kendall's tau rank correlation coefficient Spearman's rank correlation coefficient(Spearman's rho statistic) 위 세 가지 상관관계를 구하기 위해서 우선 변수 x와 y에 데이터를 입력한다. > x = rnorm(100, 50, 10) # 평균이 50이고 표준편차가 10인 100개의 정규분포를 갖는 난수발생 > y = rnorm(100, 75, 20) # 평균이 75리고 표준편차가 20인 100개의 정규분포를 갖는 난수발생 두 데이터를 한번 그래프로 나타내면 아래와 같다..