
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 단군
- 히스토그램
- linear regression
- categorical variable
- repeated measures ANOVA
- 창평
- 풍백
- t test
- 한서지리지
- ANOVA
- 독사방여기요
- Histogram
- 패수
- 선형회귀분석
- 신라
- 고구려
- 통계
- 태그를 입력해 주세요.
- 낙랑군
- 유주
- 한서
- post hoc test
- 후한서
- 기자
- R
- 통계학
- 기자조선
- spss
- 우분투
- 지리지
- Today
- Total
목록결측값 (2)
獨斷論
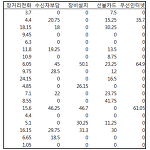 변수 recode (SPSS 사용설명서 4)
변수 recode (SPSS 사용설명서 4)
데이터를 분석하기 전에 변수의 값들을 다른 값으로 대체해야 하는 경우가 발생하는데 이럴때 사용하는 것이 variable recode 또는 variable recoding이다. 예를들어, 통신 및 전화 가입자들이 지난 한달간 요금을 납부한 내역을 통계자료로 만들었고 아래와 같다고 가정해보자. 이때 변수의 많은 값들이 0을 가지고 있는데 이는 실제로 사용한 양이 0이 아니라 해당 서비스를 원래부터 이용하지 않으므로 0이라고 입력된 것이다. 따라서 이런경우 0인 변수의 값을 그대로 사용한다면 분석에서 오류를 만들수 있다. 이럴때는 0인 변수의 값을 결측값(missing values)로 처리해 주어야만 제대로 된 통계처리결과를 얻을수 있다. 참고로 SPSS에서 결측값(missing values)는 점(' . '..
통계처리를 하기 위해 데이터를 모으다보면 missing value가 있는 subject 또는 observation이 있는 경우가 많다. 이를 해결하기 위해 가장많이 행하는 방법은 row-wise deletion 즉 어떤 변수에 결측값이 있기만 하면 그 행 전체를 버리는 것이다. SUBJECTS, x1, x2, y 1, 1, 34, 103 2, 3, NA, 54 3, 5, 54, NA 4, 7, 43, 49 만약 데이터가 위와 같다면 subjects 1과 4만 남기고 2와 3은 버린다. 이를 통계 R에서 complete.cases()라는 함수를 이용하면 쉽게 해결할수 있다. > x = c(1, 2, NA, 4, 5, 6) > y = c('a', 'b', 'c', NA, 'e', 'f') > mvindex ..