
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- t test
- spss
- post hoc test
- categorical variable
- 창평
- 단군
- 고구려
- 지리지
- 우분투
- 통계학
- 후한서
- 패수
- linear regression
- repeated measures ANOVA
- 낙랑군
- 풍백
- 선형회귀분석
- 한서
- Histogram
- R
- ANOVA
- 통계
- 태그를 입력해 주세요.
- 기자
- 히스토그램
- 신라
- 기자조선
- 한서지리지
- 유주
- 독사방여기요
- Today
- Total
목록통계 (6)
獨斷論
http://dogmas.tistory.com/186에서 사용된 데이터를 이용할 것이므로 데이터를 지웠다면 다시 수행해야 한다. t test의 가장 큰 문제는 데이터가 정규분포를 가지냐는 점이다. 정규분포의 제약이 없는 방법으로 Wilcoxon test가 있는데 dependent sample에서 어떻게 수행하는지 알아보자. 기본적인 문법은 아래와 같은데 wilcox.test(x, y = NULL, alternative = c("two.sided", "less", "greater"), mu = 0, paired = FALSE, exact = NULL, correct = TRUE, conf.int = FALSE, conf.level = 0.95, ...) Formula를 사용하지 않고 수행하려면 아래와 같이..
Dependent measures t test는 하나의 그룹의 측정값을 시간에 따라 측정했을때 얼마나 차이가 나는지 보는 것이며 repeated measures의 한 종류이다. 예를들어 식욕부진환자가 가족치료요법 전후로 몸무게가 어떻게 변화하였는지 본다면 dependent measures t test를 사용하여야만 할 것이다. 이를 R에서 수행해보자. R에는 많은 데이터베이스를 제공하는데 MASS 패키지에 anorexia가 식욕부진환자의 데이터이다. 이를 불러들이기 위하여 아래와 같이 수행한다. > data(anorexia, package="MASS") > anorexia Treat Prewt Postwt 1 Cont 80.7 80.2 2 Cont 89.4 80.1 3 Cont 91.8 86.4 4 Co..
Student's t-test를 수행하는 통계R의 명령어는 t.test()이다. R console에서 help("t.test")라고 치면 이에 대한 설명을 볼수 있다. 우선 첨부된 파일을 내려받아 통계R에서 불러들인다. 첨부파일: 이제 위 데이터파일을 R에서 불러오는데 다음과 같이 하면 된다. > temp.dat = read.csv("bodyt_heartr.csv") > temp.dat > names(temp.dat) 위와같이 실행하면 temp.dat라는 변수에 csv의 파일에 있던 데이터가 들어가게 된다. 주의할점은 현재 디렉토리와 bodyt_heartr.csv가 있는 디렉토리가 같아야 하는데 현재 R의 작업디렉토리는 getwd()를 실행하면 얻을 수 있다. 작업디릭토리를 바꾸러면 setwd("c:/t..
통계프로그램 R은 윈도우(windows)와 리눅스(linux)에 설치할 수 있다. 1) 윈도우에 설치하는 방법 아주 쉽다. http://www.r-project.org/으로 이동하여 왼쪽 메뉴에 cran을 선택하면 오른쪽 화면에 여러 서버들이 나타난다. 그러면 자신이 위치한 곳에서 가장 가까운 서버의 주소를 클릭한다. Windows라고 되어 있는 곳을 선택하여 파일을 내려받아 설치하면 된다. 한국에서 제공하는 곳은 2곳인데 http://biostat.cau.ac.kr/CRAN/ http://cran.nexr.com/ 에 가서 내려받으면 된다. 2) 리눅스 서버에서 설치하는 방법 리눅스는 각자 배포판에 R을 제공한다. 우분투는 터미널에서 아래와 같이 하면 된다. sudo apt-get install bui..
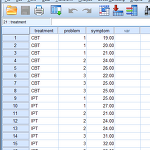 SPSS 사용법 - Descriptive Statistics Histogram
SPSS 사용법 - Descriptive Statistics Histogram
SPSS 사용법 - Descriptive Statistics (기술 통계학) 일반적으로 데이터를 가지고 통계분석을 본격적으로 하기 전에 descriptive statistics를 우선적으로 검토해봐야 데이터에 대한 전반적인 감을 알수 있고 어떤 분석을 해야할지 정할수도 있다. 예를들어 아래와 같은 3개의 변수와 16의 observation을 갖는 데이터가 있다고 가정해보자. 여기서 treatment는 증상에 대한 치료방법을 나타내고 (nominal) problem은 각 환자의 증상을 나타내며 (nominal) symptom은 증상의 심한 정도를 나타낸다 (scale 또는 ordinal) Histogram (히스토그램) 히스토그램을 그리기 위해서는 "Analyze >> Descriptive Statisti..
 SPSS 사용법 - 데이터 recode
SPSS 사용법 - 데이터 recode
SPSS 사용법 및 입문서 - 데이터 recode Ordinal 변수나 nominal 변수를 사용하다보면 이들을 한데 묶어 새로운 변수로 변환하여야 하는 경우가 있다. 예를 들어 ethnic이란 변수를 초등학교의 한 반에 존재하는 인종이라 정의한후 그 값에 따라 인종을 아래와 같이 정의하였다고 가정해보다. ethnic label 0 Korean 1 American 2 Japanese 3 Chinese 4 African 5 Russian 그리고 이제 Korean, Japanese, Chinese를 한데 묶어 0(East asian)으로 정의하고, 나머지 American, African, Russian을 한데 묶어 1(Others)로 정의하여 ethnic2라는 변수를 만들고자 한다면 다음 절차에 따라 SPS..