
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 우분투
- 풍백
- 독사방여기요
- 유주
- 태그를 입력해 주세요.
- 창평
- 패수
- 고구려
- 선형회귀분석
- 통계학
- Histogram
- categorical variable
- 기자
- 지리지
- 단군
- R
- 통계
- 한서지리지
- post hoc test
- spss
- 히스토그램
- linear regression
- 기자조선
- 신라
- 한서
- 후한서
- repeated measures ANOVA
- ANOVA
- 낙랑군
- t test
- Today
- Total
목록과학과 기술 (233)
獨斷論
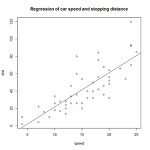 통계 R 사용설명서 6 - 간단한 그래프 그리기
통계 R 사용설명서 6 - 간단한 그래프 그리기
R에서 그릴수 있는 간단한 그래프를 그리는 방법을 알아보자 산점도(scatter plot)과 선형회귀선 일단 아래 명령줄을 실행한다. 1 2 3 4 5 6 > str(cars) > attach(cars) > plot(speed, dist) > abline(lm(dist ~ speed)) > title("Regression of car speed and stopping distance") > detach(cars) cars라는 데이터는 내장된 것으로 자동차의 정지거리와 속도와의 관계를 나타낸 것이다. 3째 줄에서 cars$speed를 X축, cars$dist를 Y축으로 하여 산점도를 그렸다. 4번째 줄에서 dist = a * speed + b의 형식으로 하는 선형회귀선을 그렸다. 주의할 것은 plot에서 ..
앞서 벡터 행렬 배열을 했고 여기서는 좀더 복잡한 data frame과 리스트와 인자에 대해서 알아보자. 1. 데이터프레임형 변수, data frame 데이터프레임의 데이터 입력 행렬과 배열은 같은 형태의 데이터만 들어갈수있지만 data frame은 다른 종류의 데이터가 들어갈수 있다는 점이 다르다. 예를 들어 대학 졸업생들의 현재 취업과 사는 곳과 나이를 조사했다고 가정한다면 다음과 같은 형태의 데이터가 존재하게 된다. ID age location company 1 30 Seoul Samsung 2 24 Pusan Baeksu 3 28 Daejon LG 4 29 Yosu LG 5 27 Ulsan Hyundai 이제 위 데이터를 R에서 입력하면 다음과 같이 할수 있다. 1 2 3 4 5 6 7 8 9 1..
R에서 사용되는 데이터형으로는 벡터(vector), 행렬(matrix), 배열(array), 데이터프레임(data frame), 리스트(list), 인자(factor) 등이 있다. 스칼라라고 그냥 쓰이는 일반적인 하나의 숫자도 있기는 하지만 쉬운거니깐 생략,, a a b c d d [1] "1" "2" "one" > class(d) [1] "character" 위에서 보는 바와 같이 벡터 d는 문자벡터가 되어 1과 2는 더이상 숫자가 아니라 문자가 된다. 벡터 안에 각각의 값을 이용하려면 대괄호를 사용한다. 1 2 3 4 5 6 > a[3] > a[5] > asum asum > a[c(1, 3, 5)] > a[3:5] 2. 행렬, matrix 행렬 데이터 입력 데이터가 행과 열로 들어가 있는 것이다. 따..
GNU R을 가지고 뭔가 분석해보기전에 꼭 필요한 기본 명령어부터 정리해보자. 수동으로 데이터 입력 c()라는 함수를 이용한다. 1 2 > height age mean(age) > sd(age) > cor(age, height) > plot(age, height) R의 도움말 기능들 아래 명령어들을 하나씩 실행해보면 무엇이 다른지 알수 있다. 1 2 3 4 5 > help.start() > help("mean") > help.search("mean") > example("mean") > apropos("mean", mode="function") 1번째줄은 도움말 시작페이지로 이동하고, 2번째줄은 mean()에 대한 도움말을 보여주며, 3번째줄은 mean이 포함된 모든 함수의 도움말을 보여준다. 4번째줄은..
 통계 R 사용설명서 2 - 텍스트 파일의 데이터 불러오기
통계 R 사용설명서 2 - 텍스트 파일의 데이터 불러오기
GNU R에서는 SPSS같은 메뉴방식의 소프트웨어와는 달리 데이터를 불러오는데 주의를 요한다. SPSS는 데이터를 불러오면서 각 단계마다 제대로 불러왔는지 확인할수있지만 R은 그렇지 못하다. R에서 텍스트 파일로 작성된 데이터 파일을 읽어들이기 전에 notepad같은 프로그램으로 열어서 다음 두 가지를 기억해 두어야 한다. 각 변수값들을 구별하는 문자는 무엇인가? 예를 들어 쉼표, 공백, 탭문자.. 데이터파일의 첫줄에 변수명이 들어가 있는가 없는가? 이는 R에서 header라고 명명할 것이다. 우선 아래 데이터 파일을 내려받아서 각자의 컴퓨터 하드디스크에 저장하자. 이때 저장한 디렉토리 경로명은 기억해두어야만 한다. 파일: 위 파일을 notepad같은 텍스트 편집기에서 열면 아래와 같은 형태이다. 첫줄은..
 통계 R 사용설명서 1 - 첫시간에는 무작정 따라하기
통계 R 사용설명서 1 - 첫시간에는 무작정 따라하기
첫시간에는 무작정 따라하기부터 해보자. 1. R 설치 통계 GNU R을 설치하려면 https://cran.r-project.org/mirrors.html로 가서 자신이 사는 곳에 가까운 곳의 서버를 선택하여 설치하면 된다. 서울대 서버의 주소는 http://healthstat.snu.ac.kr/CRAN/이다. 리눅스와 OSX와 윈도우에서 모두 사용할수 있다. R은 한번 설치한 후에 새로운 업그레이드가 나와도 업그레이드 하는 기능이 없으므로 기존버전을 지우고 새로운 업그레이드 버전을 설치해야 한다. 2. 간단한 명령 따라해보기 윈도우의 경우에는 시작버튼을 누르고 R 메뉴에서 R-i386-3.x.x나 R-x64-3.x.x를 클릭하면 된다. 리눅스는 console에서 R이라고 입력하면 된다. OSX는 써본적이..
 GLM을 이용한 반복측정 다변량분산분석 (SPSS 사용설명서 32, Repeated Measures MANOVA)
GLM을 이용한 반복측정 다변량분산분석 (SPSS 사용설명서 32, Repeated Measures MANOVA)
앞서 알아봤던 반복측정 분산분석(Repeated Measures ANOVA)에서 종속변수 한 종류가 여러번 측정되었기에(즉 sales 1~4) 다변량 분산분석이지만 그냥 ANOVA라고 명명했다. 여기서는 여러종류의 종속변수가 여러번 측정된 데이터를 가지고 분산분석을 하므로 이를 반복측정 다변량분산분석(Repeated Measures MANOVA)이라고 이름지었다. MANOVA란 multivariate ANOVA를 줄여쓴 것이다. 문제설명 심장병 환자 16명의 체중감량과제를 수행할때 성별에 따라 어떻게 달라지는지 알아보고자 한다. 이때 체중뿐만 아니라 triglyceride의 수준도 같이 측정하였으며 이 측정은 1주일마다 5번 총 5주간 실시되었다. 이제 체중과 triglyceride이 4주간 성별에 따라..
 윈도우 10 개인정보가 유출 방지되도록 설정하는 방법
윈도우 10 개인정보가 유출 방지되도록 설정하는 방법
윈도우Windows 10에서 개인정보가 유출되지 않도록 설정해야만 한다. 윈도우는 이상하게 버전이 올라갈수록 이것저것 개인의 위치정보 등을 저절로 전달되도록 설정해 놓았는데 보안상 좋지 않으므로 모두 차단해보자. 개인정보 유출을 막는 방법은 아래와 같다. 우선 윈도우버튼에서 설정을 클릭한다. 위 그림처럼 윈도우버튼 클릭 후에 "설정"을 클릭한다. 1. 개인정보 설정 바꾸기 설정 창이 뜨면 "개인정보"라고 되어 있는 것을 클릭하면 아래와 같은 창이 뜬다.그러면 "일반"을 클릭해서 모든 "개인 정보 옵션 변경"에서 "꺼짐"으로 한다. 왼쪽 메뉴 중에 "위치"를 클릭하하여"변경"을 클릭후에"꺼짐"을 클릭한다. 다음에 "음성, 수동 입력 및 입력"을 클릭한다. 아래와 같은 윈도우가 나타나면"내 정보 표시 중지"..