| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 통계학
- t test
- 유주
- 한서지리지
- 낙랑군
- 후한서
- 선형회귀분석
- 한서
- categorical variable
- post hoc test
- R
- 히스토그램
- 통계
- 독사방여기요
- 고구려
- 패수
- 신라
- 풍백
- ANOVA
- 단군
- spss
- linear regression
- 우분투
- 기자
- 기자조선
- 지리지
- repeated measures ANOVA
- 창평
- Histogram
- 태그를 입력해 주세요.
- Today
- Total
獨斷論
통계 R 사용설명서 7 - 변수생성과 recoding 본문
data frame에 새로운 변수 만들어 넣기
데이터 형 가운데 data frame이 있다는건 앞서 다뤘고 여기서는 data frame안에 변수를 하나 더 만드는 방법을 알아보자. 만드는 방법은 그냥 연산을 해서 새로운 변수에 그 연산값을 입력하면 된다.
예를 들어
mydat1이라는 data frame에 이미 x1과 x2라는 변수가 존재할때 이들 두 값의 평균과 합을 새로운 변수로 만든다고 가정하면 아래와 같이 실행하면 된다.
> x1 <- c(1, 2, 3, 4)
> x2 <- c(5, 6, 7, 8)
> mydat1 <- data.frame(x1, x2)
> mydat1$ssum <- mydat1$x1 + mydat1$x2
> mydat1$mmean <- (mydat1$x1 + mydat1$x2) / 2
> mydat1
x1 x2 ssum mmean
1 1 5 6 3
2 2 6 8 4
3 3 7 10 5
4 4 8 12 6
1과 2번 줄에서 x1과 x2에 값을 넣고
3번 줄에 이들 두 변수를 mydat1이라는 data frame으로 만들었다.
4번 줄에서 ssum이라는 변수를 새로이 생성하여 여기에 두 변수의 합을 넣었고
5번 줄에서 mmean이라는 변수를 새로이 생성하여 여기에 두 변수의 병균을 넣었다.
이렇게 하는 것보다는 다음과 같이 transform( )이라는 함수를 이용하는 것이 편하긴하다.
> mydat2 <- transform(mydat1, ssum = x1 + x2, mmean = (x1 + x2) / 2)
> mydat2
x1 x2 ssum mmean
1 1 5 6 3
2 2 6 8 4
3 3 7 10 5
4 4 8 12 6
transform( )을 이용하면 굳이 x1과 x2가 mydat1에 포함된 변수라는 것을 명시해줄 필요가 없어서 코딩이 간략해지고 보기가 쉽디ㅏ.
변수의 Recoding
여기서는 가장 많이 사용하는 recoding 방법으로 연속변수(continuous variable)를 범주형변수(categorical variable)로 바꾸는 것을 알아보자. 우선 데이터는 아래와 같다(아래 2번째 줄은 tistory의 화면이 작아서 한줄아 바뀐거라 줄번호를 넣지 않았고 13번째 줄은 R에서 엔터를 쳐서 임의로 바꾼거라 줄번호를 하나 추가하였다).
> id <- c(1, 2, 3, 4, 5)
> date <- c("May/03/2016", "Feb/12/2016", "Jul/21/2016", "Aug/18/2016", "Dec/01/2016")
> country <- c("Korea", "Japan", "China", "Korea", "Mongol")
> gender <- c("M", "F", "F", "F", "M")
> age <- c(20, 21, 53, 82, 25)
> q1 <- c(10, 3, 5, 8, 4)
> q2 <- c(7, NA, 4, 5, 9)
> q3 <- c(9, NA, 8, 9, 9)
> q4 <- c(8, 6, 10, 4, 5)
> q5 <- c(3, 6, 8, 3, 5)
>
> mydat <- data.frame(id, date, country, gender, age, q1, q2, q3, q4,
+ stringAsFactors = FALSE)
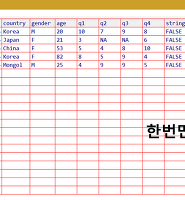
> mydat
id date country gender age q1 q2 q3 q4 stringAsFactors
1 1 May/03/2016 Korea M 20 10 7 9 8 FALSE
2 2 Feb/12/2016 Japan F 21 3 NA NA 6 FALSE
3 3 Jul/21/2016 China F 53 5 4 8 10 FALSE
4 4 Aug/18/2016 Korea F 82 8 5 9 4 FALSE
5 5 Dec/01/2016 Mongol M 25 4 9 9 5 FALSE
15번째 줄부터 최종 데이터 형태가 나오는데 다른건 볼건 없고 여기서는 age 변수를 recoding하고자 한다.
즉 age변수 값이 25보다 작으면 young, 26에서 60 사이면 middle, 61보다 크면 elder라고 recoding하여 mydat의 data frame에 새로운 변수를 만들고자 한다면 아래와 같이 하면 된다.
> mydat$agecat[mydat$age <= 25] <- "young"
> mydat$agecat[mydat$age > 25 & mydat$age <= 60] <- "middle"
> mydat$agecat[mydat$age > 60] <- "elder"
> mydat
id date country gender age q1 q2 q3 q4 stringAsFactors agecat
1 1 May/03/2016 Korea M 20 10 7 9 8 FALSE young
2 2 Feb/12/2016 Japan F 21 3 NA NA 6 FALSE young
3 3 Jul/21/2016 China F 53 5 4 8 10 FALSE middle
4 4 Aug/18/2016 Korea F 82 8 5 9 4 FALSE elder
5 5 Dec/01/2016 Mongol M 25 4 9 9 5 FALSE young
agecat라는 새로운 변수에 age의 값에 따라 young, middle, elder가 입력되었다.
이렇게 코딩을 해 놓으면 보기에 좀 지저분한데 아래와 같이 하면 좀더 간략하고 읽기 쉽다.
> mydat <- within(mydat, {
+ agecat <- NA
+ agecat[age <= 25] <- "young"
+ agecat[age > 25 & age <= 60] <- "middle"
+ agecat[age > 60] <- "elder" })
within()이라는 함수는 with()와 비슷하긴 한데 within() 안에서 변수값을 바꾸는 것이 가능하다.
위 코딩에서 agecat <- NA로 변수를 미리 생성해놓지 않으면 에러가 난다.