
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Histogram
- 패수
- 우분투
- 독사방여기요
- 낙랑군
- 후한서
- categorical variable
- t test
- 지리지
- 창평
- 단군
- linear regression
- 기자
- 기자조선
- repeated measures ANOVA
- ANOVA
- 통계학
- 한서
- 신라
- R
- 선형회귀분석
- 통계
- 유주
- spss
- 고구려
- 한서지리지
- 태그를 입력해 주세요.
- 히스토그램
- 풍백
- post hoc test
- Today
- Total
목록spss (29)
獨斷論
 GLM을 이용한 반복측정 분산분석(SPSS 사용설명서 31, Repeated Measures ANOVA)
GLM을 이용한 반복측정 분산분석(SPSS 사용설명서 31, Repeated Measures ANOVA)
음식체인점에서 새로운 메뉴를 더하고자 한다고 가정해 보자. 이때 이 메뉴를 선전하기 위해 3가지 광고를 가지고 여러 체인점에 배분하여 광고와 체인점에 따라 판매량이 어떻게 달라지는지 알아보고자 한다. 아래 데이터 파일은 이러한 음식광고와 체인점 판매량 데이터를 모은 것이다. 데이터파일: 위 데이터 파일을 내려받아 SPSS에서 읽은 후에 sav형태로 저장하면 아래와 같이 된다. GLM을 이용한 반복측정 분산분석(repeated measures ANOVA) 수행 Analyze > General Linear Model > Repeated Measures...를 클릭한다. 그러면 아래와 같은 윈도우가 나타나는데 Within-subject factor name에 week라고 쓰고 number of levels에 ..
 GLM Multivariate를 이용한 프로파일 분석 (SPSS 사용설명서 29, Profile Analysis)
GLM Multivariate를 이용한 프로파일 분석 (SPSS 사용설명서 29, Profile Analysis)
프로파일 분석이란 대개 여러개의 종속변수들이 독립변수에 따라 어떻게 변하는지 그 양상을 보고 독립변수 각각의 그룹을 판정하는 것을 말한다. 요즘 뭐 범죄수사에 프로파일러들이 많이 나오는데 범죄자들이 나타내는 양상과 일반인이 나타내는 양상이 어떻게 다른지를 알아보기때문에 프로파일러라는 말이 붙었는지도 모르겠다. 프로파일 분석은 SPSS에서 GLM Multivariate를 이용하여 쉽게 실행할 수 있다.통신회사의 고객을 예를 들어보자. 어떤 사람은 하나의 통신회사를 선택해서 꾸준히 사용하는 반면에, 어떤 사람은 싼 상품을 고르거나 통신서비스의 품질을 봐가면서 이곳 저곳 옮겨가는 사람이 있을 것이다. 통신회사는 당연히 이곳저곳 옮겨가는 사람을 반기지 아니하므로 이들을 꼭꼭 집어 내는 것이 중요하다. 통신회사를..
 z-transform을 이용하여 선형회귀분석의 공선성collinearity 문제 해결하기 (SPSS 사용설명서 18)
z-transform을 이용하여 선형회귀분석의 공선성collinearity 문제 해결하기 (SPSS 사용설명서 18)
SPSS 사용설명서 17에서 우리는 독립변수들간에 공선성 문제를 보았다. 이제 그 문제를 어떻게 해결하는지 알아보자. z-transform한 값으로 선형회귀분석 실행하기 공선성multicollinearity의 문제는 독립변수를 z-transform하여 선형회귀분석을 실행하면 그 문제를 해결할 수 있다. 선형회귀분석에 사용되었던 모든 독립변수를 z-transform하여 저장하여 보자. Analyze > Descriptive Statistics > Descriptives...를 클릭한다. Variables에 변환하고자 하는 독립변수를 설정하고아래에 Save standardized values as variables를 클릭한 후에 OK를 클릭하면 설정해두었던 변수들의 변수명에 "Z"가 붙어서 새로운 변수가 생..
 선형회귀분석 Linear Regression (SPSS 사용설명서 17)
선형회귀분석 Linear Regression (SPSS 사용설명서 17)
선형회귀분석이란 하나 이상의 독립변수로부터 종속변수의 값을 선형으로 모델링하는 것이다 독립변수는 영어로 여러가지 다른 말로 존재하는데 다음과 같다. 주로 많이 쓰는 단어를 굵게 표시하였다. independent variablespredictor variablesexplanatory variableregressorcontrolled variable, manipulated variable, exposure variablerisk factor(의학통계분야에서 쓰임) feature와 input variable(machine learning에서 쓰임) 종속변수도 영어로 여러가지 다른말로 존재한다. 역시 많이 쓰는 단어를 굵게 표시하였다. dependent variablesresponse variables 또는 r..
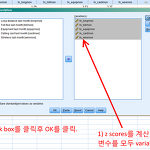 z score를 계산한후 box plot 그리기 (SPSS 사용설명서 6)
z score를 계산한후 box plot 그리기 (SPSS 사용설명서 6)
아래 첨부파일을 다운 받는다. 이것은 앞서 실행한 log transform의 결과를 저장한 것이다. 첨부파일: 첨부파일: z score를 계산하기 위 첨부파일을 SPSS에서 연 후에 아래 메뉴를 클릭한다. Analyze > Descriptive Statistics > Descriptives... z scores를 계산하고자 하는 변수를 모두 Variables로 이동시킨다. Save standardized values as variables 앞에 있는 네모난 박스를 클릭하여 z scores를 저장할수 있도록 한다. OK를 클릭한다. 만약 skewness나 kurtosis를 보고자 한다면 3번을 실행하기 전에 Options를 눌러 skewness나 kurtosis를 클릭하여 체크박스를 활성화시키면 된다. 위..
 변수 변환 variable transform (SPSS 사용설명서 5)
변수 변환 variable transform (SPSS 사용설명서 5)
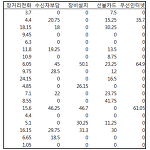
분석하고자 하는 변수의 분포가 정규분포(normal distribution)를 따르지 않을 경우에 취하는 가장 쉬운 방법이 변수변환(variable transform)이다. 우선 아래 파일을 내려받고 첨부파일: 이 파일은 앞선 내용 즉 변수 recode (SPSS 사용설명서 4)에서 0인 변수를 결측값(missing values)으로 처리한 결과를 저장해 둔 파일이다. 아래 표는 변수들에 대해서 skewness와 kurtosis를 계산해 본 것인데 모두 큰 양수로서 이런 경우에는 일반적으로 정규분포를 따른다고 가정할수가 없다. 이럴때에는 log-transform을 사용하여야 한다. 변수를 log transform 실행하기 우선 메뉴에서 아래와 같이 클릭하면 윈도우가 하나 뜰 것인데 Transform > ..
 변수 recode (SPSS 사용설명서 4)
변수 recode (SPSS 사용설명서 4)
데이터를 분석하기 전에 변수의 값들을 다른 값으로 대체해야 하는 경우가 발생하는데 이럴때 사용하는 것이 variable recode 또는 variable recoding이다. 예를들어, 통신 및 전화 가입자들이 지난 한달간 요금을 납부한 내역을 통계자료로 만들었고 아래와 같다고 가정해보자. 이때 변수의 많은 값들이 0을 가지고 있는데 이는 실제로 사용한 양이 0이 아니라 해당 서비스를 원래부터 이용하지 않으므로 0이라고 입력된 것이다. 따라서 이런경우 0인 변수의 값을 그대로 사용한다면 분석에서 오류를 만들수 있다. 이럴때는 0인 변수의 값을 결측값(missing values)로 처리해 주어야만 제대로 된 통계처리결과를 얻을수 있다. 참고로 SPSS에서 결측값(missing values)는 점(' . '..
 히스토그램Histogram 그리기 (SPSS 사용설명서 2)
히스토그램Histogram 그리기 (SPSS 사용설명서 2)
히스토그램Histogram은 대개 scale data를 가지고 그리는데 scale data라는 우리가 보통 접하는 실수형 데이터를 의미하는 말이다. 즉 연속데이터를 말한다. 히스토그램을 그리기 위해서는 우선 메뉴에서 아래와 같이 클릭한다. Analyze > Descriptive Statistics > Frequencies... 그러면 아래와 같은 윈도우가 하나 뜨는데1) Reset을 눌러 이미 있던 variables를 지우고, Amount of last sale(sale)을 선택한 후에 화살표 같은 걸 클릭하여 variables로 옮겨 놓는다. 2) Statistics를 누르면 Frequencies: Statistics 창이 하나 뜨는데 여기서 보고자 하는 여러가지 것들을 체크하면 나중에 OUTPUT에 ..