| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 우분투
- repeated measures ANOVA
- 유주
- ANOVA
- 신라
- 단군
- post hoc test
- 기자조선
- 지리지
- 한서지리지
- 패수
- Histogram
- 후한서
- R
- 낙랑군
- 통계
- 독사방여기요
- 풍백
- categorical variable
- 통계학
- linear regression
- spss
- 창평
- 한서
- 태그를 입력해 주세요.
- 히스토그램
- 고구려
- 선형회귀분석
- t test
- 기자
- Today
- Total
獨斷論
SPSS 사용법 - Binary Logistic Regression 본문
SPSS 사용법 - Binary Logistic Regression
Binary logistic regression은 종속변수가 0과 1을 갖는 categorical variable을 독립변수로부터 예측할때 사용하는 모델이다. 종속변수가 2가지 이상의 값을 갖는 categorical variable일때는 multinomial logistic regression을 이용하지만 여기서는 다루지 않는다.
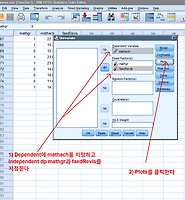
우선 첨부파일을 다운받아서 SPSS에서 import하여야 한다. 쉼표로 나누어진 txt파일이므로 적절한 import과정을 거쳐야만 한다.
첨부파일: logreg.csv
logreg.csv
위 파일을 제대로 SPSS에서 불러들였다면 아래와 같은 변수들이 나타날 것이다.

alg2는 algebra2를 수강하였는지 안하였는지 나타내는 것이고
gender는 성별
mosaic은 mosaic test의 결과이며
visual은 visual test의 결과이고
parEduc는 부모의 교육 수준을 나타낸다.
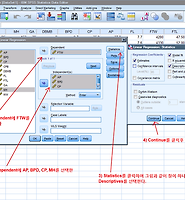
이제 gender, mosaic, visual, parEduc를 독립변수로 하고 alg2를 예측하는 모델을 binary logistic regression으로 만들어보자.
우선 "Analyze >> Regression >> Binary Logistic..."을 클릭한다.

위와 같은 순서대로 실행하면 아래와 같은 결과를 얻을 수 있다.
Block 0

우선 block 0는 logistic regression 모델에서 독립변수를 사용하지 않고 오직 상수값만 있었을때 정보를 나타낸다.
위 classification table의 53.3%의 값은 아무런 모델을 사용하지 않고 algebra 2를 선택하지 않았다고 하였을때 맞출 확률을 나타낸다.

위 표의 제목은 variables not in the equation이므로 block 0에서 위 변수 4개가 사용되지 않았음을 보여준다. 하지만 visual과 parEduc의 significance가 0.05보다 작으므로 alg2에 통계적으로 의미있는 영향을 미침을 알수 있다.
Block 1
Block 1은 독립변수 즉 predictor를 사용하였을때 결과를 보여준다. 우선 Omnibus Tests of Model Coefficients를 보자

Omnibus tests of model coefficients는 모든 독립변수를 모델에 사용하였을때 전체모델의 significance를 보여주는 것이며 여기서 p = 0.00 < 0.05이므로 binary logistic regression 모델이 통계적으로 유의미함을 의미한다.
R square는 모델의 종속변수가 얼마나 데이터의 variability를 잘설명해주는가를 나타내는 것이다. 보통 Nageikerke R2를 Cox & Snell R2보다 더 많이 사용하는데 왜냐하면 Cox & Snell R2는 이론적으로 최대값을 1이라고 보장할수 없기때문이다.
-2log likelihood statistic은 얼마나 모델이 데이터를 잘 나타내지 못했냐를 나타내는 수치이다. 따라서 이 수치는 작을수록 좋다. 대개 100보다 작으면 좋다고 보며 20보다 작은 아주 좋은 것을 나타낸다.
-2log와 관련된 p-value가 Hosmer and Lemeshow Test이다. 위 표에서 Hosmer and Lemeshow test의 p-value가 0.699이므로 대체로 모델이 데이터를 잘 나타내주었다고 볼수 있다. Hosmer and Lemeshow test statistic의 p-value는 0.05보다 커야한다.

이제 classification table을 보자. alg2를 선택하지 않았다는 예측이 맞을 확률은 82.5%이고, alg2를 선택하였다는 예측이 맞을 확률은 71,4%이며 전체적으로 모델의 예측이 맞을 확률은 77.3%임을 보여준다.
그리고 binary logistic regression 모델에서 significant한 변수는 parEdu와 visual임을 보여주는데 왜냐하면 p-value가 각각 0.004와 0.011이기때문이다.
visual 변수의 Exp(B)의 값은 1.209인데 이는 visual이 1만큼 증가할때 alg2를 선택하지 않을 확률에 대한 선택할 확률이 20.9% 증가함을 보여주는 것이다. 이와 똑같이 parEduc의 Exp(B)의 값이 1.462이므로 parEduc의 값이 1 증가함에 따라서 alg2를 선택하지 않을 확률에 대하여 선택할 확률이 46.2% 증가함을 보여준다.