
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- categorical variable
- Histogram
- R
- repeated measures ANOVA
- 유주
- 낙랑군
- 지리지
- 태그를 입력해 주세요.
- 패수
- 고구려
- linear regression
- spss
- 단군
- ANOVA
- 풍백
- t test
- 기자
- 한서지리지
- 히스토그램
- 선형회귀분석
- 한서
- post hoc test
- 후한서
- 통계
- 창평
- 독사방여기요
- 우분투
- 통계학
- 신라
- 기자조선
- Today
- Total
목록독단론 (436)
獨斷論

확률변수 X의 적률생성함수 X가 이산확률변수이고 pmf가 f(x)이고 support가 S일때 $$M(t) = E( e^{tX} ) = \sum_{x \in S} e^{tx} f(x)$$ 를 X의 적률생성함수라고 한다. 이때 t는 $-h \lt t \lt h$인 h가 존재해야만 한다. 예제 Binomial 확률변수의 적률생성함수 구하기 $\begin{align} M(t) &= E\left(e^{tx} \right)\\ &= \sum_{x=0}^n e^{tx} f(x) \\ &= \sum_{x=0}^n e^{tx} \dbinom{n}{x} p^x (1-p)^{(n-x)} \\ &= \sum_{x=0}^n \dbinom{n}{x} (p e^t )^x (1-p)^{(n-x)} \\ &= \left[ (1-p) ..
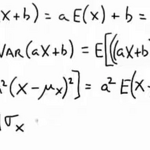 확률이론 정리3. 이산분포(Discrete distribution)
확률이론 정리3. 이산분포(Discrete distribution)
Probability Mass fucntion(p.m.f) 이산확률변수 $X$에 대하여 이산질량함수(probability mass function) $P(X = x) = f(x)$는 다음을 만족한다. $P(X = x) = f(x) \gt 0$ $\sum\limits_{x \in S} f(x) = 1$ $P(X \in A) = \sum\limits_{x \in A} f(x)$ Cumulative distribution function(CDF) 확률변수 $X$의 누적분포함수는 다음과 같이 정의된다. $$F_X (t) = P(X \le t)$$ CDF의 성질들 $F_X (t)$는 증가하는 함수이다. t의 범위는 $-\infty \lt t \lt \infty$ $0 \le F_X (t) \le 1$ 확률변수 X..
 확률이론 정리 2. 베이즈 정리(Bayes theorem)
확률이론 정리 2. 베이즈 정리(Bayes theorem)
예제 전등을 만드는 3개의 공장 A, B, C에서 결함이 있는 전등을 만들 확률이 아래와 같다고 가정하자. 임의로 선택한 전등이 결함이 있을때 ,공장 C에서 만들었을 확률은 얼마인가? 고장난 전등을 선택한 사건을 D라고 하면 위 문제는 $P(C | D)$를 구하면 된다. 베이즈 정리(Bayes' Theorem) m개의 사건 B1, B2, ..., Bm이 다음 두조건을 만족한다고 가정하자. Mutually exclusive $B_i \cap B_j=\emptyset$ for $i \ne j$ exhaustive $\mathbf{S} = B_1 \cup B_2 \cup \cdots B_m$ 따라서 P(A)는 $\begin{align} P(A) &= P(A \cap B_1 ) + P(A \cap B_2 ) +..
 확률이론 정리 1
확률이론 정리 1
모집단으로부터 표본을 취하여 모집단의 물리량을 추정한다. 표본공간(Sample space, outcome space), S) 모든 가능한 랜던샘플의 집합이다. "잠을 푹 잤는가?"라는 질문이라면 표본공간은 S= {yes, no} 질문이 하루에 잠을 몇시간 자는가라면 $\textbf{S} = \left\{ h : h \ge 0 \right\}$ 한달에 여자들이 남자들보다 우는 날이 더 많은가라는 질문이라면 $\textbf{S} = \left\{0, 1, 2, \cdots, 31 \right\}$ Events 무작위실험을 했을때 표본공간의 부분집합을 말한다. 주로 대문자 A, B, C 등으로 나타낸다. 무작위실험을 한번 했을때 나오는 결과는 outcome이라고 한다. $$A \subset \textbf{S}..
 통계기초 정리 9. 단순선형회귀
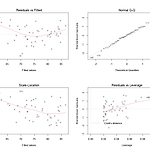
통계기초 정리 9. 단순선형회귀
단순선형회귀모델 $$\hat{y} = b_0 + b_1 x$$ 여기서 $\hat{y} : $ y의 예측값 $b_0 :$ y 절편 $b_1 :$ 기울기 주로 사용되는 용어설명하면 Explanatory variable 독립변수 $x$를 지칭한다. predictor variable이라고도 부른다. Response variable 종속변수 $y$를 지칭한다. outcome variable이라고도 부른다. 잔차(Residual, $e_i$) 예측값과 측정값과의 차이를 말한다. $$e_i = y_i - \hat{y}_i$$ Sum of squared residuals 위 잔차의 제곱의 합을 구하면 $$ SSE = \sum_i { \left( y_i - \hat{y}_i \right)^2 } $$ 단순선형회귀의 가정..
 통계기초 정리 8. 상관관계
통계기초 정리 8. 상관관계
Pearson's correlation 모집단의 상관관계는 $rho$로 나타내고 샘플의 상관관계는 $r$로 나타낸다. 두 샘플 x와 y에 대한 상관관계를 구하려면 $$ r = \frac {1} {n-1} \sum \left( \frac {x - \bar{x}} {s_x}\right) \left( \frac{y - \bar{y}} {s_y} \right)$$ 여기서 $s_x$는 샘플 x의 표준편차이고 $s_y$는 샘플 y의 표준편차이다. $\bar{x}$는 샘플 x의 평균이다. 이제 두 샘플의 상관관계를 구해보자 데이터 exam.df = read.csv("d:/tmp/exam.csv", header = TRUE) x = exam.df$Quiz_Average y = exam.df$Final mean_x = ..
어떤 사건이 시간당 발생할 속도(비율)이 평균적으로 이미 알려져 있고 이 값을 $r$라고 가정하자. 즉 일정시간 $N$당 이 사건이 $k$번 일어난다고 이미 알려져 있다면 $r = k / N$이다. 이때 이 사건이 $t$라는 시간동안 $x$번 일어날 확률을 구하면 이는 Poisson distribution에 해당되며 아래와 같이 구한다. $$Pr(x) = \frac {(r \, t)^x e^{-rt}} {x!}$$ 여기서 $rt$를 $\lambda$로 주로 나타내고 rate parameter라고도 부른다. Probability mass function을 $\lambda$와 같이 나타내면 $$f(x; \lambda) = Pr(X=x) = \frac {\lambda^x e^{-\lambda}} {x!}$$ ..