
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 신라
- 기자
- 기자조선
- 풍백
- spss
- categorical variable
- 낙랑군
- post hoc test
- 유주
- 선형회귀분석
- 단군
- 한서지리지
- 후한서
- t test
- 창평
- 독사방여기요
- 패수
- linear regression
- 히스토그램
- 우분투
- 태그를 입력해 주세요.
- 지리지
- 고구려
- 통계학
- Histogram
- R
- ANOVA
- repeated measures ANOVA
- 한서
- 통계
- Today
- Total
목록과학과 기술/R 통계 (70)
獨斷論
 다중회귀분석 multiple regression analysis (통계 R 초급 - 12)
다중회귀분석 multiple regression analysis (통계 R 초급 - 12)
다중회귀분석을 실행하기 위하여 R에서 제공하는 데이터를 아래와 같이 불러들인다. > st77 = data.frame(state.x77) > str(st77) 'data.frame':50 obs. of 8 variables: $ Population: num 3615 365 2212 2110 21198 ... $ Income : num 3624 6315 4530 3378 5114 ... $ Illiteracy: num 2.1 1.5 1.8 1.9 1.1 0.7 1.1 0.9 1.3 2 ... $ Life.Exp : num 69 69.3 70.5 70.7 71.7 ... $ Murder : num 15.1 11.3 7.8 10.1 10.3 6.8 3.1 6.2 10.7 13.9 ... $ HS.Grad : n..
 선형회귀분석 linear regression analysis (통계 R 초급 - 11)
선형회귀분석 linear regression analysis (통계 R 초급 - 11)
R 통계패키지에서 제공하는 선형회귀분석 명령어는 매우 다양한데 여기서는 가장 많이 사용하는 한 가지에 대해서만 알아보기로 하겠다. 우선 데이터를 읽어들이고 lm()을 이용하여 선형회귀분석을 실행하면 된다. 이때 formula를 입력하여야 하는데 보통 아래와 같다. (Dependent Variables) ~ (Independent Variables) 그러면 R 패키지에 들어있는 cats라는 데이터를 이용하여 선형회귀분석을 수행해 보기로 하자. > data(cats) > lm(cats$Hwt ~ cats$Bwt) Call: lm(formula = cats$Hwt ~ cats$Bwt) Coefficients: (Intercept) cats$Bwt -0.3567 4.0341 cats데이터에서 Hwt는 심장무게이..
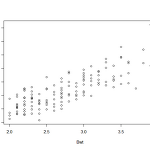 간단한 상관관계correlation와 공분산행렬covariance matrix (통계 R 초급 - 10)
간단한 상관관계correlation와 공분산행렬covariance matrix (통계 R 초급 - 10)
상관관계(correlation)는 두 변수사이에 어떠한 관계가 있는지 알아보는 것이며 여기에서는 관계가 서로 선형(linear)인것만 가정한다. R의 MASS 패키지에 있는 cats이라는 데이터를 사용할 것이므로 다음과 같이 입력하면 된다. > library("MASS") > data(cats) 고양이 성별에 따른 몸무게와 심장무게를 갖는 데이터이다. str(cats)라고 입력하면 어떠한 데이터인지 알수 있는데 Bwt는 몸무게이고 Hwt는 심장무게이다. 몸무게와 심장무게를 그래프로 그리려면 아래와 같이 하면 된다. > with(cats, plot(Bwt, Hwt)) 그래프로부터 강한 선형관계가 있음을 알수있고 이를 수치적으로 알아보기위하여 Pearson product moment correlation c..
 Factorial Between-Subjects ANOVA - 두번째 (통계 R 초급 - 9)
Factorial Between-Subjects ANOVA - 두번째 (통계 R 초급 - 9)
앞서 해봤던 Factorial between-subjects ANOVA 첫번째에 이어서 두번째 시간에서는 본격적으로 ANOVA를 수행해 보기로 하자. 우선 R에서 어떻게 ANOVA 모델을 입력하는지 그 대략을 살펴보면 아래와 같다. symbol example meaning + + x include this variable - - x delete this variable : x : z include the interaction between these variables * x * z include these variables and the interactions between them / x / z nesting: include z nested within x | x | z conditioning: inc..
 Factorial Between-Subjects ANOVA - 첫번째 (통계 R 초급 - 8)
Factorial Between-Subjects ANOVA - 첫번째 (통계 R 초급 - 8)
이번에 할것은 Factorial Between-Subjects ANOVA이다. 우선 R에서 제공하는 ToothGrowth 데이터를 이용한다. 이를 불러오기 위해서는 아래와 같이 실행하면 된다. > data(ToothGrowth) > str(ToothGrowth) 'data.frame': 60 obs. of 3 variables: $ len : num 4.2 11.5 7.3 5.8 6.4 10 11.2 11.2 5.2 7 ... $ supp: Factor w/ 2 levels "OJ","VC": 2 2 2 2 2 2 2 2 2 2 ... $ dose: num 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 ... > 데이터구조는 dataframe이고 60개의 observation에 ..
 통계 R용 GUI 프로그램 Rkward
통계 R용 GUI 프로그램 Rkward
무료 통계프로그램 R에서 사용할수 있는 GUI 중에 사용하기 좋은것이 RStudio말고 하나 더 있다. 주로 리눅스 KDE용으로 개발된 Rkward인데 이제 이것을 windows에서도 사용할수 있다. 사용방법은 간단. 아래 링크로 이동한 후에 최신버전 bundle로 다운받는다. http://sourceforge.net/projects/rkwardextras/files/Windows/ 현재 2013년 11월 8일 최신버전은 0.6.1 self-extracting파일로 되어 있으므로 실행시키면 프로그램 압축이 저절로 풀린다. 재밌는건 bundle이다보니 설치도 필요 없고 R 프로그램까지 같이 딸려 온다는거... 그러니깐 설치가 아니라 하드디스크에 그냥 복사해서 쓰는거다. 다운받은걸 실행하면 아래같이 뜨는데 ..
 R plot에서 사용되는 pch에 따른 심벌 종류를 알아보자
R plot에서 사용되는 pch에 따른 심벌 종류를 알아보자
R은 커맨드로 입력되는 프로그램이라 그래프 그릴때 좀 어렵다. 특히 심벌을 바꿀때는 옵션을 바꾸어 줘야 하는데 머리에 외우는 일이란 참으로 불가능한 일이다. 그래서 참고로 여기 자주 이용되는 몇개의 심벌을 올려놓으니 참조하기 바란다. 예를 들어 아래처럼 수행해서 두 그림을 비교해보자.> x = rnorm(100) > plot(x, pch=1) > plot(x, pch=2)
 Post Hoc 테스트 (통계 R 초급 - 8)
Post Hoc 테스트 (통계 R 초급 - 8)
ANOVA를 수행한 후에는 꼭 해야할 일이 post hoc 테스트인데 이것은 각 그룹들 사이에 어떤 한 쌍의 그룹이 가장 큰 차이를 보여주었는지를 알아보는 것이다. 앞서 ANOVA는 단지 p-value만 보여주어 샘플 데이터의 그룹 평균값의 차이가 통계적으로 의미있는지 없는지 찾아봤다면, post hoc 테스트는 그 의미있는 통계적 차이가 어떤 특정 그룹에 의해서 생겨났는지를 보는 것이라고 이해하면 된다. 수행방법은 아래와 같다. > data(InsectSprays) # 데이터를 불러들인다 > aov.results = aov(count ~ spray, data=InsectSprays) # ANOVA 수행 > summary(aov.results) # 결과 출력 Df Sum Sq Mean Sq F value..