
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 기자조선
- R
- 통계학
- 후한서
- Histogram
- 풍백
- post hoc test
- 한서
- 패수
- 독사방여기요
- linear regression
- 태그를 입력해 주세요.
- 신라
- 지리지
- spss
- 우분투
- repeated measures ANOVA
- 히스토그램
- 통계
- 선형회귀분석
- 고구려
- categorical variable
- 단군
- t test
- 한서지리지
- ANOVA
- 낙랑군
- 유주
- 창평
- 기자
- Today
- Total
목록과학과 기술/SPSS (61)
獨斷論
 One-way ANOVA에서 contrast를 사용하기 (SPSS 사용설명서 12)
One-way ANOVA에서 contrast를 사용하기 (SPSS 사용설명서 12)
앞서 one-way ANOVA를 수행한 결과를 먼저 보면 (http://dogmas.tistory.com/350) 가장 높은 점수를 준 그룹은 3번과 4번인데 과연 3번과 4번이 서로 차이가 있는지 궁금해 할수도 있다. 만약 통계적으로 3과 4가 다르지 않다면 가장 많은 점수를 준 그룹은 3과 4라고 해야할 것이고 3과 4가 통계적으로 다르다면 가장 많은 점수를 준 그룹은 4라고 해야할 것이다. 이제 3과 4가 서로 다른지 contrast를 써서 알아보자. 데이터 파일은 앞서 사용한 dvdplayers.csv를 이용한다. One-way ANOVA와 똑같이 아래 순서로 우선 클릭한다. Analyze > Compare Means > One-Way ANOVA...그러면 아래와 같이 창이 뜬다. 우선 ANOVA..
 One-way ANOVA (SPSS 사용설명서 11)
One-way ANOVA (SPSS 사용설명서 11)
One-way ANOVA는 두개 이상의 그룹 사이의 평균값이 다른지 알아보는 것이다. 우선 아래 csv 파일을 받아서 SPSS에서 불러들인 후에 sav파일로 저장한다. 제대로 했다면 다음과 같이 나올것이다. 위 데이터는 회사에서 새로운 DVD player를 만들었고 그 제품들이 연령대별로 어떤 호감도를 가지고 있는지를 조사한 후에 연령대를 6개의 그룹으로 나눈 것이다. dvdscore는 제품의 호감도이고 agegroup은 연령대 그룹이다. One-way ANOVA를 수행하기 위해서는 우선 아래와 같이 수행한다. 우선 Analyze > Compare Means > One-Way ANOVA...를 클릭한다. 그러면 아래와 같은 윈도우가 뜬다. 위 그림에서 설명한대로1) 왼쪽 네모칸에 있던 dvdscore를 ..
 Independent-samples t test (SPSS 사용설명서 10)
Independent-samples t test (SPSS 사용설명서 10)
Independent-samples t test는 독립적으로 얻어진 두 데이터가 얼마나 다른지를 보는 것이다. 예를들어 신용카드 회사에서 한 그룹은 할인된 이자율을 적용하는 광고를 받고 다른 그룹은 표준 이자율을 적용받는 광고를 받았다고 하자. 이때 두 그룹에서 사용하는 돈의 액수가 차이가 있는지 알아볼수 있다.우선 아래 데이터를 받고 SPSS에서 읽고 creditadv.sav로 저장한다. 잘되었다면 아래와 같은 형태가 될것이다. 샘플의 observation 갯수는 500id는 참가자의 ID를 나타내고insert는 광고의 종류, 0은 표준이자율이고 1이 새로 광고한 이자율 dollars는 쓴 돈을 나타낸다. 이제 independent t test를 실행해보자. Analyze > Compare Means ..
 Paired-samples t test (SPSS 사용설명서 9)
Paired-samples t test (SPSS 사용설명서 9)
Paired-samples t test란 같은 실험 참가자의 처치 전후의 결과를 비교하는 것이다. 예를 들어 머리가 좋아지는 약을 개발했다고 가정했을때 이 약을 먹기 전의 IQ과 먹고 난 뒤의 IQ를 측정해서 얼마나 달라지는지를 보면 되는 것이다. 이때 두 IQ의 차이가 통계적으로 의미가 있는지 없는 보는 것이 paired samples t test이다. 이때 null hypothesis는 "두 IQ의 차이는 0이다"이다. 그러면 이제 데이터를 가지고 실제적인 문제를 풀어보도록하자. 우선 아래 데이터 파일을 받아서 SPSS에서 불러들인후에 Ctrl+S를 눌러 diets.sav로 저장한다. 잘 불러들이고 저장했다면 아래와 같이 나올 것이다. 이 데이터는 어떤 다이어트프로그램을 개발하여 그 프로그램을 참가한..
 One-sample t test (SPSS 사용설명서 8)
One-sample t test (SPSS 사용설명서 8)
One-sample t test는 샘플의 평균이 얼마나 우리가 원하는 값과 멀어져 있는지 보는 것이다.우선 아래 파일을 SPSS에 읽어들인다. csv파일이므로 적절히 읽어들이면 된다. ㅋㅋ 위 파일을 잘 불러들였다면 아래와 같이 나올 것이다.그러면 File >> Save를 클릭하거나 Ctrl+S를 눌러서 brakes.sav라고 저장하자. 위 데이터는 공장에서 만드는 브레이크를 무작위로 샘플링하여 그 지름을 mm 단위로 측정한 것이다. 그리고 이 지름은 322 mm가 되어야 정상이다. 이제 모집단의 브레이크의 지름이 322보다 얼마나 차이가 나는지 t test를 통하여 알아보자. 우선 Analyze >> Compare Means >> One-Sample T Test를 클릭한다. 그러면 아래와 같은 창이 뜨..
 SPSS에서 두 변수의 히스토그램을 한 그래프에 그리기
SPSS에서 두 변수의 히스토그램을 한 그래프에 그리기
SPSS에서는 변수 두 개의 히스토그램을 하나의 그래프에 그리는 것은 좀 어렵다. 일반적으로 사용하는 GUI 메뉴 클릭으로는 안되고 SYNTAX를 사용해야 한다. 아래와 같이 하면 됨 데이터가 들어있는 sheet의 이름이 기본적으로 DataSet0라고 가정하고 변수는 두개 ... salary와 salbegin... * Chart Builder. GGRAPH /GRAPHDATASET NAME="DataSet0" VARIABLES=salary salbegin MISSING=LISTWISE REPORTMISSING=NO /GRAPHSPEC SOURCE=INLINE. BEGIN GPL SOURCE: s=userSource(id("DataSet0")) DATA: salary=col(source(s), name("..
 Box plot의 median, hinge, whisker, outlier (SPSS 사용설명서 7)
Box plot의 median, hinge, whisker, outlier (SPSS 사용설명서 7)
Box plot에 대해서 좀더 알아보자. Box plot은 또한 box and whisker plot이라고도 부른다. 대체적으로 위와 같이 생겼는데 하나씩 알아보면 중앙값(median, 2rd quartile, 50th percentile)은 박스 안에 있는 굵은 선이다. Hinges 또는 박스의 위와 아래 경계선: 박스의 아래쪽 경계선은 25th percentile 또는 1st quartile이 되는 지점이고 박스의 위쪽 경계선은 75th percentile 또는 3rd quartile이 되는 지점이다. Whisker는 이상치(outlier, 극단치)를 제외한 최대와 최소값까지를 말한다. 위 그림에서는 수직으로 점선이 그려져 있는데 이것이 whisker이며 이상치를 제외한 최대값과 최소값에 각각 수평으..
 z score를 계산한후 box plot 그리기 (SPSS 사용설명서 6)
z score를 계산한후 box plot 그리기 (SPSS 사용설명서 6)
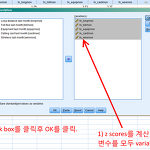
아래 첨부파일을 다운 받는다. 이것은 앞서 실행한 log transform의 결과를 저장한 것이다. 첨부파일: 첨부파일: z score를 계산하기 위 첨부파일을 SPSS에서 연 후에 아래 메뉴를 클릭한다. Analyze > Descriptive Statistics > Descriptives... z scores를 계산하고자 하는 변수를 모두 Variables로 이동시킨다. Save standardized values as variables 앞에 있는 네모난 박스를 클릭하여 z scores를 저장할수 있도록 한다. OK를 클릭한다. 만약 skewness나 kurtosis를 보고자 한다면 3번을 실행하기 전에 Options를 눌러 skewness나 kurtosis를 클릭하여 체크박스를 활성화시키면 된다. 위..