
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 우분투
- ANOVA
- 태그를 입력해 주세요.
- 통계학
- repeated measures ANOVA
- linear regression
- 선형회귀분석
- post hoc test
- 낙랑군
- 기자
- 히스토그램
- 유주
- 후한서
- 창평
- 한서
- 독사방여기요
- categorical variable
- 한서지리지
- 패수
- 단군
- spss
- 풍백
- R
- 통계
- Histogram
- 고구려
- t test
- 신라
- 기자조선
- 지리지
- Today
- Total
목록과학과 기술 (233)
獨斷論
 SPSS 사용법 - Dependent t Test
SPSS 사용법 - Dependent t Test
SPSS 사용법 - Dependent t Test (대응표본 t 검정) 앞선 Independent t test와는 달리 dependent t test는 같은 실험집단이 실험처치를 받은 후에 어떻게 달라지는가를 검사하는 방법이다. 예를 들어 아래와 같은 데이터를 가지고 있다고 가정해 보자. 실험참가자는 모두 10명이며 실험처치를 받기 전에 측정값과 받은 후의 측정값을 모아 놓은 것이다. 이제 실험처치가 효과적으로 측정값을 바꾸어 놓았는지를 보기 위하여 dependent t test를 실행해 보기로 하자. "Analyze >> Compare Means >> Compared-Samples T Test"를 클릭하면 아래와 같은 대화상자가 나타난다. Dependent t test는 두 개의 변수를 하나의 짝을 이..
 SPSS 사용법 - Independent t test
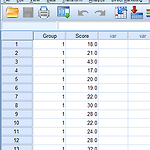
SPSS 사용법 - Independent t test
SPSS 사용법 - Independent t test Independent t test는 두 개의 다른 group의 평균을 비교할때 사용한다. 우선 아래 첨부파일을 다운로드 받는다. 첨부파일 이 파일은 쉼표로 구분된 데이터파일이며 header에 변수명이 지정되어 있지 않다. 우선 SPSS를 실행시켜 "File >> Open >> Data"를 클릭한다. "Open Data" 대화상자가 열리면 "File of Type"에서 Text(*.txt, *.dat, *.csv)를 선택후 independent_t.csv를 open하여 comma delimited로 파일을 읽어들인다. (Wizard형식의 파일 import이므로 자세한 그림은 생략한다. 질문이 있으면 아래 comment를 남기면 된다) Variable V..
 SPSS 사용법 - Correlation
SPSS 사용법 - Correlation
SPSS 사용법 - Correlation (상관관계) 우선 아래와 같이 데이터를 입력한다. 위 데이터에서 Parent는 어떤검사에 대한 parent score이고 Child는 child score를 나타낸다. 위 두개의 score가 서로 언떤 상관관계가 있는지 알아보고자 할때 SPSS에서 제공하는 correlate를 사용할수있다. 우선, "Analyze >> Correlate >> Bivariate"를 클릭하면 아래와 같은 대화상자가 나타난다. 위 그림과 같이 실행하면 아래와 같은 결과를 얻을 수 있다. Parent score와 child score의 pearson correlation coefficient sms 0.756이고 p=0.011 < 0.05이므로 통계적으로 significant함을 알수 있..
 SPSS 사용법 - Descriptive Statistics Normality Test
SPSS 사용법 - Descriptive Statistics Normality Test
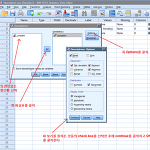
SPSS 사용법 - Descriptive Statistics Normality Test (정규분포 테스트) 대부분의 통계분석은 데이터가 정규분포임을 가정하는 경우가 많으므로 분석을 하기 전에 자신이 가진 데이터가 정규분포에서 얼마나 떨어져 있는지 테스트해 보는 것이 중요하다. 우선 "Analyze >> Descriptive Statistics >> Explore"를 클릭하면 아래와 같은 대화상자가 나타난다. 위 그림에 나타난 순서대로 실행을 하면 아래와 여러 결과를 얻을 수 있는데 그 중에서 아래 그림은 test of normality만 표시하였다. 위 표에서 Degrees of Freedom은 16으로 subjects의 갯수를 나타내고 Kolmogorov-Smirnov test statistics의 값..
 SPSS 사용법 - Descriptive Statistics 평균 표준편차 skewness
SPSS 사용법 - Descriptive Statistics 평균 표준편차 skewness
SPSS 사용법 - Descriptive Statistics 본격적인 통계분석을 하기 전에 데이터의 평균 분산 비대칭도(skewness)등을 구하여 대충의 감을 잡는 것이 중요하다. 여기서 또 중요한 것은 평균과 같은 descriptive statistics를 SPSS에서 구할때에 scale변수로 정의되어 있어야만 한다는 점이다. 평균 표준편차 skewness(비대칭도) 우선 "Analyze >> Descriptive Statistics >> Descriptives"를 클릭하면 아래와 같은 대화상자가 나타난다. 왼쪽에 나타나는 변수는 "Variable View"에서 "Numeric"으로 정의된 변수만 나타나는데 measure가 scale일 경우에만 의미가 있으므로 유의한다. 위 그림에 나타난 순서대로 실..
 SPSS 사용법 - Data View의 Value 사용법
SPSS 사용법 - Data View의 Value 사용법
SPSS 사용법 - Data View의 Value 사용법 앞선 histogram 사용법(http://dogmas.tistory.com/121)의 결과가 problem을 1, 2, 3으로 입력하였기에 무엇을 뜻하는지 알기가 어렵다. 데이터가 작은 경우에는 기억하기 쉽지만 데이터가 몇만개 정도 된다면 이 1, 2, 3이 무엇을 나타내는지 쉽게 기억해 내기 어렵다. 이에 대비하여 숫자로 입력한 nominal 데이터의 각각의 값이 무엇을 뜻하는지 입력할수 있다. 우선 "Data View" tab을 클릭하여 변수 "problem"의 "Values"가 "none" 옆에 "..."으로 표시된 곳을 클릭하면 아래와 같은 대화창이 나타난다. 위와 같이 각 값에 대한 설명을 입력한후 Histogram을 http://dog..
 SPSS 사용법 - Descriptive Statistics Histogram
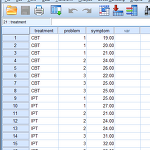
SPSS 사용법 - Descriptive Statistics Histogram
SPSS 사용법 - Descriptive Statistics (기술 통계학) 일반적으로 데이터를 가지고 통계분석을 본격적으로 하기 전에 descriptive statistics를 우선적으로 검토해봐야 데이터에 대한 전반적인 감을 알수 있고 어떤 분석을 해야할지 정할수도 있다. 예를들어 아래와 같은 3개의 변수와 16의 observation을 갖는 데이터가 있다고 가정해보자. 여기서 treatment는 증상에 대한 치료방법을 나타내고 (nominal) problem은 각 환자의 증상을 나타내며 (nominal) symptom은 증상의 심한 정도를 나타낸다 (scale 또는 ordinal) Histogram (히스토그램) 히스토그램을 그리기 위해서는 "Analyze >> Descriptive Statisti..
 SPSS 사용법 - 데이터 recode
SPSS 사용법 - 데이터 recode
SPSS 사용법 및 입문서 - 데이터 recode Ordinal 변수나 nominal 변수를 사용하다보면 이들을 한데 묶어 새로운 변수로 변환하여야 하는 경우가 있다. 예를 들어 ethnic이란 변수를 초등학교의 한 반에 존재하는 인종이라 정의한후 그 값에 따라 인종을 아래와 같이 정의하였다고 가정해보다. ethnic label 0 Korean 1 American 2 Japanese 3 Chinese 4 African 5 Russian 그리고 이제 Korean, Japanese, Chinese를 한데 묶어 0(East asian)으로 정의하고, 나머지 American, African, Russian을 한데 묶어 1(Others)로 정의하여 ethnic2라는 변수를 만들고자 한다면 다음 절차에 따라 SPS..