
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 기자조선
- 통계
- 한서
- 후한서
- 낙랑군
- 우분투
- 패수
- ANOVA
- categorical variable
- 유주
- 단군
- 신라
- 선형회귀분석
- repeated measures ANOVA
- 지리지
- 통계학
- 풍백
- 한서지리지
- 기자
- 독사방여기요
- spss
- linear regression
- post hoc test
- 고구려
- t test
- 창평
- 히스토그램
- Histogram
- R
- 태그를 입력해 주세요.
- Today
- Total
목록독단론 (438)
獨斷論
 우분투에서 octave 3.8을 설치해보자..
우분투에서 octave 3.8을 설치해보자..
Octave 3.8이 나왔는데 여기에는 matlab처럼 GUI가 있어서 이제 toolbox만 제대로 갖추어진다면 비싼 matlab 같은건 안사도 된다. 아직 쉽게 설치할수있는 이진파일은 없고 소스코드만 존재.. MacOSX에서는 있는것 같기도 하다... 우분투에서 아래와 같이 소스코드를 컴파일해서 설치할수있다고 하여 지금 설치중... 터미널에서 아래와 같이 실행 이건 소스코드를 /home/사용자이름/Downloads에 저장하는 것이다.wget -P ~/Downloads http://ftp.gnu.org/pub/gnu/octave/octave-3.8.0.tar.bz2 압축파일을 풀고 해당 디렉토리로 이동tar -C ~/Downloads -xvf ~/Downloads/octave-3.8.0.tar.bz2 c..
통계처리를 하기 위해 데이터를 모으다보면 missing value가 있는 subject 또는 observation이 있는 경우가 많다. 이를 해결하기 위해 가장많이 행하는 방법은 row-wise deletion 즉 어떤 변수에 결측값이 있기만 하면 그 행 전체를 버리는 것이다. SUBJECTS, x1, x2, y 1, 1, 34, 103 2, 3, NA, 54 3, 5, 54, NA 4, 7, 43, 49 만약 데이터가 위와 같다면 subjects 1과 4만 남기고 2와 3은 버린다. 이를 통계 R에서 complete.cases()라는 함수를 이용하면 쉽게 해결할수 있다. > x = c(1, 2, NA, 4, 5, 6) > y = c('a', 'b', 'c', NA, 'e', 'f') > mvindex ..
기자를 한자로 箕子로 쓰는데 子를 어떤이는 성씨라고 하기도 하고 어떤이는 子爵이라고 하기도 한다. 근데 이 子는 夷狄의 왕을 폄하하는데도 사용하였다. 춘추좌전을 보자. 魯僖公 二十有七年春杞子來朝 27년 봄에 기자(杞子)가 내조했다. 傳에 이렇게 써있다. 二十七年春 杞桓公來朝 用夷禮 故曰子(주1) 公卑杞 杞不共也(주2) 27년 봄에 기환공(杞桓公)이 와서 조견(朝見)하였다. 조견할 때 이적(夷狄)의 예(禮)를 사용하였기 때문에 자(子)라고 한 것이다. 공公이 기자杞子를 비천卑賤하게 여겼으니, 이는 기자杞子가 공경恭敬하지 않았기 때문이다. 주1 杞 先代之後 而迫於東夷 風俗雜壞 言語衣服有時而夷 故杞子卒 傳言其夷也 今稱朝者 始於朝禮 終而不全 異於介葛盧 故唯貶其爵 기杞는 선대의 후손이지만 동이와 가까워서 그 풍속..
 다중회귀분석 multiple regression analysis (통계 R 초급 - 12)
다중회귀분석 multiple regression analysis (통계 R 초급 - 12)
다중회귀분석을 실행하기 위하여 R에서 제공하는 데이터를 아래와 같이 불러들인다. > st77 = data.frame(state.x77) > str(st77) 'data.frame':50 obs. of 8 variables: $ Population: num 3615 365 2212 2110 21198 ... $ Income : num 3624 6315 4530 3378 5114 ... $ Illiteracy: num 2.1 1.5 1.8 1.9 1.1 0.7 1.1 0.9 1.3 2 ... $ Life.Exp : num 69 69.3 70.5 70.7 71.7 ... $ Murder : num 15.1 11.3 7.8 10.1 10.3 6.8 3.1 6.2 10.7 13.9 ... $ HS.Grad : n..
 선형회귀분석 linear regression analysis (통계 R 초급 - 11)
선형회귀분석 linear regression analysis (통계 R 초급 - 11)
R 통계패키지에서 제공하는 선형회귀분석 명령어는 매우 다양한데 여기서는 가장 많이 사용하는 한 가지에 대해서만 알아보기로 하겠다. 우선 데이터를 읽어들이고 lm()을 이용하여 선형회귀분석을 실행하면 된다. 이때 formula를 입력하여야 하는데 보통 아래와 같다. (Dependent Variables) ~ (Independent Variables) 그러면 R 패키지에 들어있는 cats라는 데이터를 이용하여 선형회귀분석을 수행해 보기로 하자. > data(cats) > lm(cats$Hwt ~ cats$Bwt) Call: lm(formula = cats$Hwt ~ cats$Bwt) Coefficients: (Intercept) cats$Bwt -0.3567 4.0341 cats데이터에서 Hwt는 심장무게이..
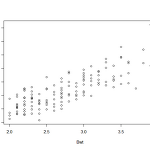 간단한 상관관계correlation와 공분산행렬covariance matrix (통계 R 초급 - 10)
간단한 상관관계correlation와 공분산행렬covariance matrix (통계 R 초급 - 10)
상관관계(correlation)는 두 변수사이에 어떠한 관계가 있는지 알아보는 것이며 여기에서는 관계가 서로 선형(linear)인것만 가정한다. R의 MASS 패키지에 있는 cats이라는 데이터를 사용할 것이므로 다음과 같이 입력하면 된다. > library("MASS") > data(cats) 고양이 성별에 따른 몸무게와 심장무게를 갖는 데이터이다. str(cats)라고 입력하면 어떠한 데이터인지 알수 있는데 Bwt는 몸무게이고 Hwt는 심장무게이다. 몸무게와 심장무게를 그래프로 그리려면 아래와 같이 하면 된다. > with(cats, plot(Bwt, Hwt)) 그래프로부터 강한 선형관계가 있음을 알수있고 이를 수치적으로 알아보기위하여 Pearson product moment correlation c..
 Factorial Between-Subjects ANOVA - 두번째 (통계 R 초급 - 9)
Factorial Between-Subjects ANOVA - 두번째 (통계 R 초급 - 9)
앞서 해봤던 Factorial between-subjects ANOVA 첫번째에 이어서 두번째 시간에서는 본격적으로 ANOVA를 수행해 보기로 하자. 우선 R에서 어떻게 ANOVA 모델을 입력하는지 그 대략을 살펴보면 아래와 같다. symbol example meaning + + x include this variable - - x delete this variable : x : z include the interaction between these variables * x * z include these variables and the interactions between them / x / z nesting: include z nested within x | x | z conditioning: inc..
 Factorial Between-Subjects ANOVA - 첫번째 (통계 R 초급 - 8)
Factorial Between-Subjects ANOVA - 첫번째 (통계 R 초급 - 8)
이번에 할것은 Factorial Between-Subjects ANOVA이다. 우선 R에서 제공하는 ToothGrowth 데이터를 이용한다. 이를 불러오기 위해서는 아래와 같이 실행하면 된다. > data(ToothGrowth) > str(ToothGrowth) 'data.frame': 60 obs. of 3 variables: $ len : num 4.2 11.5 7.3 5.8 6.4 10 11.2 11.2 5.2 7 ... $ supp: Factor w/ 2 levels "OJ","VC": 2 2 2 2 2 2 2 2 2 2 ... $ dose: num 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 ... > 데이터구조는 dataframe이고 60개의 observation에 ..